Architecture Bytes - Apache Spark
Learn about Apache Spark, a fast and general-purpose cluster computing system
Motivation
Before Spark, big data processing was done by using Hadoop MapReduce. There are several issues with MapReduce:
- Network and Disk IO costs: Intermediate data has to be read and written to disk and shuffled across machines which is slow
- Not suitable for iterative (i.e. modifying small amounts of data repeatedly) processing, such as interactive workflows.
Spark stores most of its intermediate results in memory making it much faster, especially for iterative processing. However, it does read and write to disk if the memory is insufficient.
Introduction
Spark revolves around the concept of a resilient distributed dataset (RDD), which is a fault-tolerant collection of elements that can be operated on in parallel. RDDs support two types of operations:
- Transformations - Which create a new dataset from an existing one.
- Actions - Which return a value to the driver program after running a computation on the dataset.
RDDs
- Resilient: Able to achieve fault tolerance through lineages.
- Distributed Datasets: Represent a collection of objects that is distributed over machines
Operations
Transformation: Transform one RDD to another RDD. Transformation are lazy and will not be executed until an action is called on it.
Actions: Trigger Spark to compute a result from a series of transformations.
Distributed Processing
- RDDs are actually distributed across machines
- The transformations and actions are executed in parallel. The results are only sent to the driver in the final step.
Caching
Once a RDD action is called, Spark will run all the transformations from the initial RDD to the final RDD. No intermediate RDD is stored after the result has been computed. Therefore, if there are subsequent steps that use these intermediate RDD, it is important to cache them. Spark will save the intermediate RDDs in the caches of the individual workers. If the memory of the worker is full or nearly full, a LRU eviction strategy is used.

 Example of caching in Spark
Example of caching in Spark
Here messages is used twice. It is important to cache the intermediate RDD to prevent re-computation again.
Note that apart from cache(), persist(options) also exists. The latter is more flexible, allowing to store in memory, disk or off-heap memory.
DAG
- Internally, Spark creates a graph (“directed acyclic graph”) which represents all the RDD objects and how they will be transformed.
- Transformations construct this graph; actions trigger computations on it.
Narrow Dependencies
Narrow dependencies are where each partition of the parent RDD is used by at most 1 partition of the child RDD. E.g. map, flatMap, filter, contains
Wide Dependencies
Wide dependencies are the opposite (each partition of parent RDD is used by multiple partitions of the child RDD). E.g. reduceByKey, groupBy, orderBy
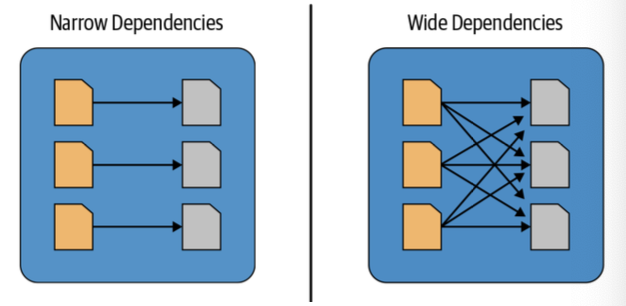
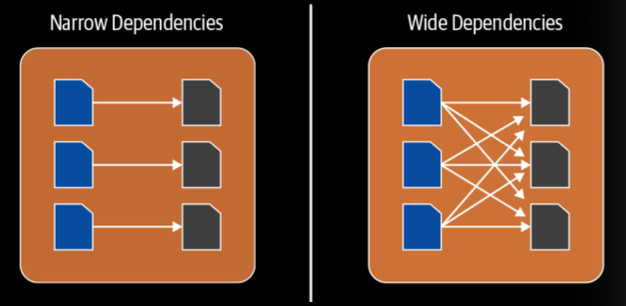 Narrow and wide dependencies in Spark
Narrow and wide dependencies in Spark
Computation
- Within stages, Spark performs consecutive transformation on the same machines.
- Across stages, data needs to be shuffled, i.e. exchanged across partitions, in a process very similar to map-reduce, which involves writing intermediate results to disk.
- This is because the data needs to be transferred across the network between executors, and writing to disk provides a reliable way to store and exchange the shuffled data.
- Minimizing shuffling is good practice for improving performance.
Fault Tolerance
Spark uses lineage approach. If a worker node goes down, we replace it by a new worker node, and use the graph (DAG) to recompute the data in the lost partition.
Architecture
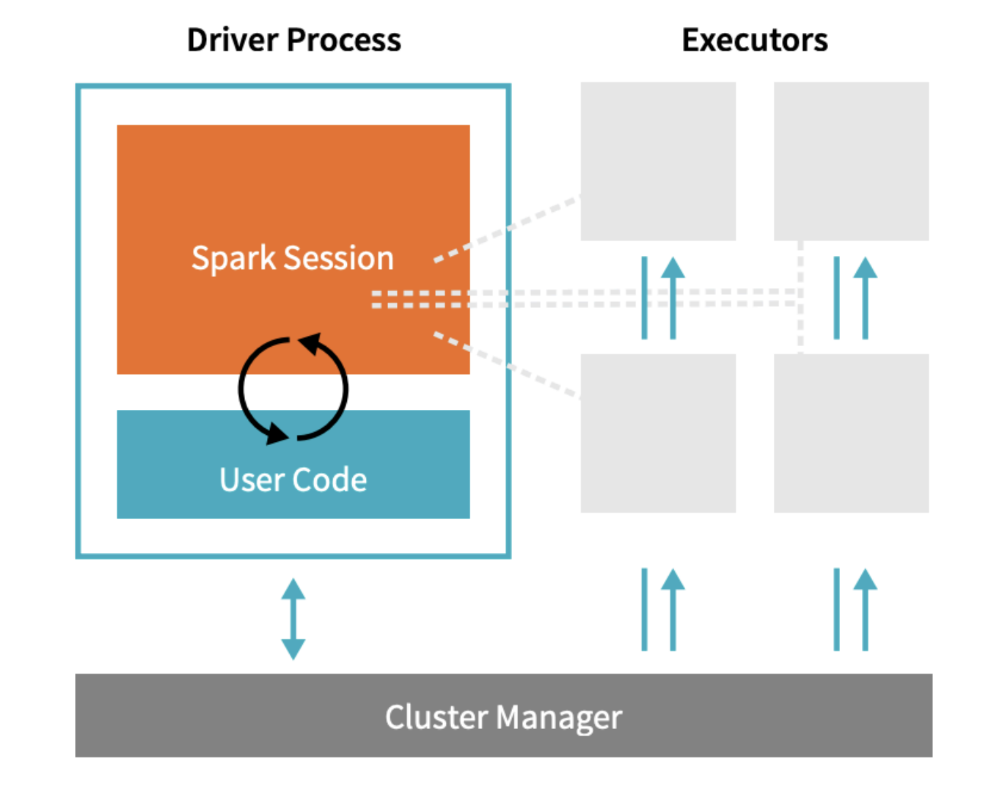
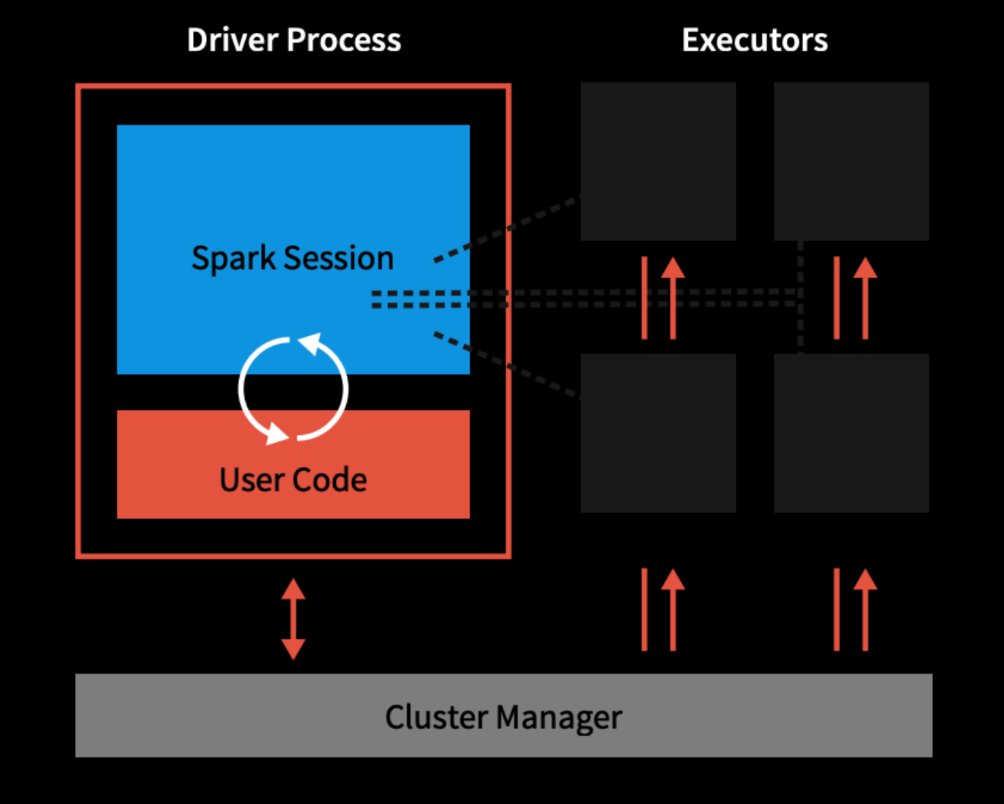 Spark architecture
Spark architecture
- Driver Process responds to user input, manages the Spark application etc., and distributes work to Executors, which run the code assigned to them and send the results back to the driver
- Cluster Manager (can be Spark’s standalone cluster manager, YARN, Mesos or Kubernetes) allocates resources when the application requests it
- In local mode, all these processes run on the same machine